LATCH TYPES
There are hundreds of
different types of latch, most of which you are unlikely to encounter
in any meaningful way when you are working with SQL Server. While latch
waits will occasionally show up in sys.dm_os_wait_stats, you normally have to actively search for them. As a rule, they don’t come to you.
Typically, latches are divided into two distinct
categories in SQL Server. They either serve the buffer pool, in which
case they are known as BUF latches (showing up as PAGELATCH or PAGEIOLATCH in sys.dm_os_wait_stats and aggregated into the BUFFER latch class in sys.dm_os_latch_stats), or they don’t, in which case they are grouped under the non-buffer (Non-BUF) heading. This is a slight generalization, but it’s adequate for our purposes here.
If you run the following query, you will get a list of more than 150 latch types (code file Ch7LatchTypes.sql):
SELECT *
FROM sys.dm_os_latch_stats;
If you order this data by any of the three numeric columns, you’ll see that by far the most common latch type is BUFFER. If you look at the contents of sys.dm_os_wait_stats, you’ll see latches that are prefixed with LATCH_, PAGELATCH_ and PAGEIOLATCH_.
The LATCH_
waits are all for the Non-BUF types. There are many of these, ensuring
that the database engine can handle many of the operations it needs to
perform. If you look through those latch types in sys.dm_os_latch_stats, you will see things such as BACKUP_FILE_HANDLE latches, SERVICE_BROKER latches, and even VERSIONING latches, which may be involved in your transactions depending on the isolation level.
The PAGELATCH_
latches are like those you saw in the example earlier. Data from a user
object is needed, and to ensure that it can be written or read
consistently, a latch is acquired. These buffer latches can be applied
to all kinds of pages, including Page Free Space (PFS), Global
Allocation Map (GAM), Shared Global Allocation Map (SGAM), and Index
Allocation Map (IAM) pages.
The PAGEIOLATCH_
latch types are used when data is being moved from disk into RAM. An
I/O operation is in play when a I/O latch is needed. In some ways, this
is the easiest type latch wait to troubleshoot, as high PAGEIOLATCH
wait times imply that the I/O subsystem cannot keep up. If this is the
case, and you can’t mitigate the problem through I/O reduction or
increased RAM, you have a nice argument for buying that faster storage
you’ve been wanting.
LATCH MODES
Latch modes are far easier to
contemplate than lock modes.
If you query sys.dm_os_wait_stats as follows (code file Ch7LatchModes.sql), you’ll see the different modes listed there. This query is looking at the PAGELATCH_ latches, but you could use it for PAGEIOLATCH_ or LATCH_ instead and see the same latch modes. They are the two character combinations following the underscore.
SELECT *
FROM sys.dm_os_wait_stats
where wait_type like 'PAGELATCH%';
Six latch modes are listed, usually in the
following order: NL, KP, SH, UP, EX, DT. While there’s no guarantee
they’ll appear in this order if you don’t specify an ORDER BY clause, this is the order you’ll likely see.
NL
NL is an internal Null latch. You don’t
need to consider it. It essentially means no latch is being used, so it
isn’t even recorded under normal conditions.
KP
KP is a Keep latch, used to indicate that a particular page is needed for something and shouldn’t be destroyed.
SH
This refers to a Shared latch, which is needed to read the data from a page.
UP
This is an Update latch, which
indicates that a page is being updated, but not the table data within
it. This is not related to the T-SQL UPDATE
statement, which requires an Exclusive latch (the next mode discussed).
Update latches are more common for internal operations, such as
maintaining PFS pages or updating the checksum bits on a page. Because
the type of data being updated is not needed to service queries, it is
compatible with a shared latch, but not another Update latch.
EX
When data is being explicitly changed
or added, an Exclusive latch is required. This is the most common type
of latch for troubleshooting purposes, as two EX latches cannot be held
on the same page at the same time. While this is also true of UP
latches, EX latches are the more common of the two.
DT
The presence of this latch, the Destroy
latch, means that the page is in the process of being removed from
memory. A page that is deleted picks up a DT latch from the lazywriter
process while the record of the page is removed. Bear in mind that this
does not necessarily mean that the data is being deleted — it may
simply be removed from the buffer cache, with a copy of the data still
residing on the disk. However, multiple steps are involved in removing
a page from the buffer cache, as the SQL Server engine maintains a hash
table that lists which pages are currently in memory (otherwise, it
wouldn’t know the memory address of the page). The DT latch cannot be
taken out if any other kind of latch is on the page, which makes the KP
latch much more significant. A page that is needed but isn’t yet being
read or written would use a KP latch to prevent the DT latch from being
acquired.
Latch Compatibility
The five latch types (ignoring the internal NL latch) are compatible as shown in Table 1. Note how much simpler it is than the lock compatibility equivalent.
TABLE 1: Latch Types
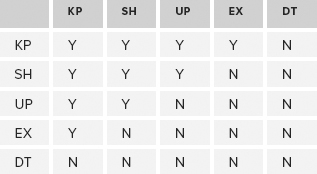
A page that has an EX latch on it can have a KP
latch applied, but not any other type. Similarly, the only type of
latch that can exist on a page that needs an EX latch applied is a KP
latch. Unlike the lock compatibility table, there are no surprises in
the latch compatibility table.
Despite the simplicity of this table, be sure you
feel comfortable with the various scenarios that are possible. Consider
the page with the shared latch that allows an update latch to be
acquired on it (for an internal process to make a change to non-user
data), but not an exclusive latch (which would mean that actual data
was changing). Consider the page that is being destroyed and doesn’t
allow anything else to come near it; and the update latch, which
prevents other update latches.
Grant Order
In any system, particularly as the
number of processor threads grows, a number of requests will be queued
for a particular page. For example, a number of pages might be
inserting data into a table while others are reading that data, and the
data may need to be moved from disk, and so on.
For a page that has no latches on it, the first
process that wants a latch will be granted one. That’s straightforward;
but when more processes start coming along, the behavior is slightly
different. A KP latch will skip the queue completely — unless there is
a DT latch on the page, a KP latch will jump ahead and keep it alive.
Other latches will wait, joining the queue (even
if there is compatibility between the two — another slight difference
between lock behavior and latch behavior). When the current latch is
released, the first latch in the queue can be granted, but here
something special happens. Any other latch in the queue that is
compatible with that first latch (which is being granted) will be
allowed, even if there are incompatible locks in front of it. It’s like
the nightclub bouncer who takes the first person in the queue but also
looks through it for anyone else who can be let in. This way, the next
latch type in line is always granted, but there’s an opportunity for
other latches to jump in through the closing door at the same time.
Typically, latches are taken out for short periods, so the incompatible
latches shouldn’t have to wait for too long, depending on what’s going
on. The algorithm might not seem fair, but it does make sure that
concurrency can apply when possible.
Latch Waits
You’ve already looked at wait types such as PAGELATCH_EX and PAGEIOLATCH_SH, but there’s more to discuss about this in order to provide a complete picture of the information in sys.dm_os_wait_stats.
As described earlier, some latches can come into contention with one
another. This is intended and necessary as part of the need to
serialize access. However, as with locking, this does raise the
prospect of blocking, and consequently latch waiting.
A latch wait
can be defined as a latch request that cannot be granted immediately.
This could result from one of two reasons. First, the latch is already
being accessed. As stated earlier, new latches are evaluated at the
closure of the existing request. The second reason follows from the
first. When the wait list is accessed following the closure of the
previous latch, the next wait in that list may be a conflicting lock
with other waits. If you refer back to the grant order example, when an
EX request is processed, no other latch may be granted at the same time.
Unfortunately, there are side effects to keeping
latches lightweight. They do not provide full blocking task information
when forced to wait. Blocking task information is only known when the
latch is held in one of the write latch modes — namely, UP, EX, and DT.
Given that only one task can hold a latch in one of these modes at any
one time, identifying it as the blocker is relatively straightforward.
Suppose the blocker is a read latch (either KP or SH) — this latch
could be held by many tasks simultaneously, so identifying the task
that is the blocker is not always possible. When the blocker is known,
all waiting tasks will report that the one task is the cause of the
block. Logically, then, the wait type is that of the requester, not the
blocker.
It is possible for this blocking information to
change during a single task’s wait. Consider this example: A UP latch
has been granted. Another task has requested a DT latch and therefore
has been forced to wait. At this point the blocker is reported, as the
latch held is a UP latch. By definition this can only be a single task.
Before the UP latch has been released, a KP latch sneaks in and is
granted (remember that KPs don’t respect the FIFO rules). The UP latch
is then released, leaving the KP in place to do its thing. It can no
longer be guaranteed that this KP is the only latch in play. The DT
latch is still forced to wait because the KP is already there. However,
now there is no serialized write latch mode in effect and the blocking
information is lost. What can be said though at this point is that the
blocker is either a KP latch or a SH latch.
It is also possible for a task to be
shown to block itself in certain scenarios (although it is somewhat of
an illusion, as the blocking is probably being done by internal threads
that belong to the database engine rather than the actual task). This
is due to the asynchronous nature of data access. Again, this is
probably best illustrated with an example. Consider this scenario: A
read request is made to the Buffer Manager, but when the hash table is
checked, it is found that the page doesn’t exist in memory. An I/O
request is scheduled and a PAGIOLATCH_EX latch
is taken (assume granted) on a BUF structure to allow the page to be
read into the data page for the buffer. The task that initiated the
request will then submit an SH latch to read the data. However, this
can appear as being blocked by the EX latch if there is a lag
retrieving the page from disk.

